회고
Cafe24 OBS -> AWS S3 마이그레이션
안녕하세요.
운영 중인 서비스에서 지속적으로 "이미지 로딩이 느리다"는 문의가 들어왔습니다.
처음부터 개발에 참여하지 않아 정확한 이유는 파악하기 어려웠지만, 해당 사이트는 웹 서버와 DB는 AWS 서비스를 사용하는데 S3만 Cafe24를 사용하고 있었습니다. 아마도 초기 개발 당시 비용을 고려한 선택으로 보입니다.
웹 서버와 DB는 안정성을 위해 AWS를 선택했다고 하지만, Cafe24 OBS에서 AWS S3로 전환한다고 해서 이미지 로딩 속도가 정말 개선될까? 이 의문을 해소하기 위해 두 서비스의 차이점을 분석하고 마이그레이션은 진행했습니다.
차이점
네트워크 지연과 데이터 경로 최적화
Cafe24 OBS의 문제:
웹 서버(EC2)와 DB(RDS)는 AWS 서울 리전에 있는데 이미지만 Cafe24 망에 있으면, 사용자 요청마다 서로 다른 네트워크망을 경유해야 합니다. 이를 멀티 클라우드라고 부르기도 하지만, 최적화되지 않은 구조에서는 불필요한 네트워크 홉(Hop)이 발생해 응답 속도가 느려집니다.
AWS S3의 장점:
서버와 스토리지가 같은 AWS 인프라 내부에 있어 내부 통신 최적화가 가능합니다. 특히 서버 사이드에서 이미지를 가공하거나 메타데이터를 읽어올 때, 외부망을 거치지 않아 속도 차이가 큽니다.
HTTP 프로토콜과 동시성 처리
Cafe24 OBS의 한계:
일반적인 웹 호스팅 환경에서는 HTTP/1.1 방식을 사용하는 경우가 많습니다. 브라우저가 한 번에 6~8개 정도의 이미지만 동시에 로딩할 수 있어서, 썸네일이 많은 리스트 페이지에서는 순차적으로 로딩되며 병목 현상이 발생합니다.
AWS S3 + CloudFront의 강점:
AWS로 전환하면 전용 CDN인 CloudFront를 쉽게 연결할 수 있습니다. HTTP/2 또는 HTTP/3을 적용하면 수십 개의 썸네일을 하나의 연결로 동시에 가져올 수 있어 체감 속도가 크게 향상됩니다.
확장성과 스토리지 안정성
Cafe24 OBS:
고정된 대역폭이나 공유 자원을 사용하기 때문에 사용자가 몰리면 이미지 로딩이 끊기는 현상이 발생하기 쉽습니다.
AWS S3:
초당 수천 건의 요청도 안정적으로 처리하는 무제한급 대역폭을 제공합니다. 데이터 내구성이 99.999999999%로 설계되어 운영 환경에서 안정적인 서비스를 보장합니다.
마이그레이션 아키텍처
서비스 중단 없는 이전을 위해 마이그레이션과 실시간 이중 업데이트를 병행하는 하이브리드 전략을 사용했습니다.
실시간 이중 업로드 시스템
새로운 파일이 업로드될 때 신/구 저장소 모두에 데이터를 저장하여 데이터 공백을 차단하였습니다.
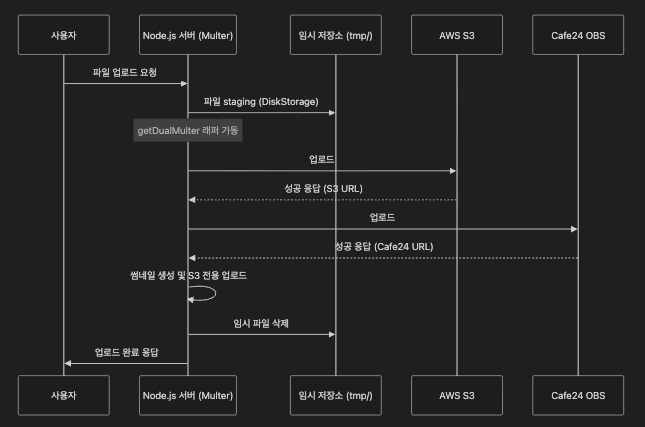
- Dual Multer: Cafe24와 AWS에 같이 업로드하여 데이터 정합성을 유지했습니다.
- Dynamic Prefixing: 호스트명을 분석하여
localhost나dev환경에서는 자동으로 파일명에s3_dev_접두사를 붙여 운영과 개발 데이터를 분리했습니다.
실제 효과
- 신규 업로드 데이터의 100% 이중화 달성
- 마이그레이션 기간 중 데이터 손실 0건
- 기존 시스템과의 하위 호환성 유지
카테고리별 특화 마이그레이션
단순 복사가 아닌, 데이터 성격에 따른 맞춤형 처리 로직을 적용했습니다.
미디어
- 이동 대상 : 1 (이미지), 2 (비디오) 타입 데이터 전체
- 이미지 최적화 :
sharp라이브러리를 사용하여 원본에서 특정 썸네일을 실시간으로 생성 - 비디오 처리: 기존에 추출된 ffmpeg 기반 썸네일을 다운로드하여 S3에 다시 최적화된 형태로 저장
첨부 파일
- 다양한 MIME 타입 지원 : 이미지뿐만 아니라 PDF, DOC, XLS 등 다양한 문서 파일을 포함
- 무결성 유지 : 실시간성이 중요한 채팅 특성상 리사이즈 단계를 생략하고 원본 그대로의 무결성을 유지
데이터 정합성 및 검증
대규모 데이터 이동에서 가장 중요한 파일 유실 방지를 위해 다중 검증 로직을 구현했습니다.
존재 유무 직접 검증
업로드 API의 성공 응답에만 의존하지 않고, AWS SDK의 HeadObjectCommand를 호출하여 S3에 객체가 실제로 물리적으로 존재하는지 2차 확인합니다.
MIME 타입 스마트 감지
단순히 확장자에 의존하지 않고, getContentType 유틸리티를 통해 파일의 실제 바이너리 구조를 분석하거나 sharp메타데이터를 활용하여 정확한 Content-Type을 할당했습니다.
통계 기반 관리
실패한 ID 목록을 별도 통계(stats)로 산출하여 누락된 파일에 대한 재처리가 용이하도록 설계했습니다.
{
"total": 100,
"success": 95,
"failed": 5,
"uploadedVerified": 94 // S3 존재 확인 결과
}
쿼리 확인
DB에서 쿼리를 직접 실행하여 마이그레이션 전후 비교하여 확인했습니다.
-- 마이그레이션 전후 비교 통계 예시
SELECT
COUNT(*) as total_records,
-- 기존 파일 통계
COUNT(CASE WHEN file_path IS NOT NULL AND file_path != '' THEN 1 END) as original_file_count,
-- S3 파일 통계
COUNT(CASE WHEN s3_file_path IS NOT NULL AND s3_file_path != '' THEN 1 END) as s3_file_count,
-- 마이그레이션 완료 여부 (기존 파일이 있으면서 S3 파일도 있는 경우)
COUNT(CASE WHEN (file_path IS NOT NULL AND file_path != '') AND (s3_file_path IS NOT NULL AND s3_file_path != '') THEN 1 END) as migrated_count,
-- 마이그레이션 미완료 (기존 파일은 있지만 S3 파일이 없는 경우)
COUNT(CASE WHEN (file_path IS NOT NULL AND file_path != '') AND (s3_file_path IS NULL OR s3_file_path = '') THEN 1 END) as not_migrated_count
FROM messages
WHERE del_yn = 'N';
주요 트러블슈팅
레거시 데이터의 URL 파편화
- 문제 : DB에 저장된 이미지 경로가 프로토콜(https://)이 없거나, temp/ 경로로 시작하는 등 일관성이 없었습니다.
케이스 1: "temp/uploads/image.jpg" (프로토콜 없음)
케이스 2: "//cdn.cafe24.com/uploads/image.jpg" (프로토콜 생략)
케이스 3: "http://old-domain.com/image.jpg" (구 도메인)
케이스 4: "/uploads/image.jpg" (상대 경로)
- 해결 :
imageHelper.js에normalizeUrl함수를 구현했습니다. 다양한 케이스에 대응하는 규칙 기반 정규화를 통해, 어떤 형태의 레거시 경로라도 정확한 소스를 찾아 다운로드할 수 있도록 보정했습니다.
// ex
const normalizeUrl = (path, baseUrl) => {
if (!path) return null;
// 1. 이미 완전한 URL인 경우
if (path.startsWith('http://') || path.startsWith('https://')) {
return path;
}
// 2. 프로토콜 생략 형태 (//로 시작)
if (path.startsWith('//')) {
return `https:${path}`;
}
// 3. temp/ 로 시작하는 특수 케이스
if (path.startsWith('temp/')) {
return `${baseUrl}/${path}`;
}
// 4. 절대 경로 형태 (/로 시작)
if (path.startsWith('/')) {
return `${baseUrl}${path}`;
}
// 5. 상대 경로
return `${baseUrl}/${path}`;
};
대량 데이터 처리 시의 네트워크 부하
- 문제 : 수만 건의 이미지를 한 번에 처리할 경우 서버 네트워크 부하와 타임아웃이 발생할 수 있었습니다.
- 해결 : 모든 데이터를 한 번에 처리하지 않고, 테이블별로 독립적인 배치 프로세스를 구성했습니다. 각 파트별로 분산 처리를 수행하여 시스템 안정성을 확보했습니다.
업로드 성공 여부의 불확실성
- 문제 : API 호출이 성공하더라도 실제 S3 버킷에 파일이 물리적으로 존재하는지, 또는 바이너리가 깨지지 않았는지에 대한 의문이 있었습니다.
- 해결 : 위에서 설명드렸던 존재 유무 직접 검증 로직을 통해 모든 마이그레이션 파일에 대해
HeadObject확인을 강제했습니다. 이 과정에서 발견된 누락 건들을 별도 로그로 관리하고 재처리함으로써 데이터 마이그레이션 100%를 달성했습니다.
성능 및 개선 사항
정성적 개선
- 사용자 경험 향상
- 게시판 목록 스크롤 시 이미지 끊김 현상 해소
- 채팅방 이미지 전송 후 즉시 표시 (이전: 1-2초 지연)
- 운영 안정성 확보
- 트래픽 급증 시에도 안정적 서비스 제공
- 개발 생산성 향상
- 모든 인프라가 AWS로 통합되어 관리 포인트 단순화
마치며
이번 마이그레이션을 통해 느낀점이 몇가지가 있습니다.
1. API 응답만 믿지 말 것
완료 응답 코드만으로는 실제 성공 여부를 보장할 수 없습니다. 특히 분산 시스템에서는 반드시 물리적 검증 단계가 필요합니다.
2. 네트워크는 언제나 불안정하다
재시도 로직, 타임아웃, 지수 백오프는 필수입니다. 한 번에 성공할 거란 보장이 없기 때문에 실패 케이스에 대한 처리가 무엇보다 중요합니다.
3. 레거시 데이터는 생각보다 복잡하다
오래된 시스템일수록 데이터 정규화가 되어있지 않고, 예상치 못한 변수들이 존재합니다. 다양한 URL 패턴을 분석하고 정규화하는 능력이 필요했고, 이를 통해 데이터 마이그레이션의 복잡성을 체감할 수 있었습니다.