회고
LLM 기반 의상 추천 서비스 성능 최적화
기존에 의상 추천 서비스 로직을 만들어 사용했지만, 요구사항에 따라 LLM을 추가해 의상 추천을 하는 로직을 짰고, 간단하게 설명을 하자면
OpenAI gpt 모델을 사용했고, gpt에게 날씨, 해당 유저의 옷 등 정보들을 넘기고 JSON 형태로 반환시켜 날씨에 맞게 옷을 추천해달라하고, 프론트에 바로 넘겨주는 형태로 만들었다.
문제점
정상적으로 실행되지만, 문제가 두가지 있었다.
일관성 부족
첫 번째 문제로는 gpt의 답변이 일관되지 않았다. 의도와는 다른 답변을 반환했는데, 예를 들면 상의를 두가지 추천하다던가, 하의만 추천한다던가 이러한 의도와 다르고 자연스럽지 않은 의상 추천을 했기에 더 자연스러운 추천 흐름을 만들어야 했다.
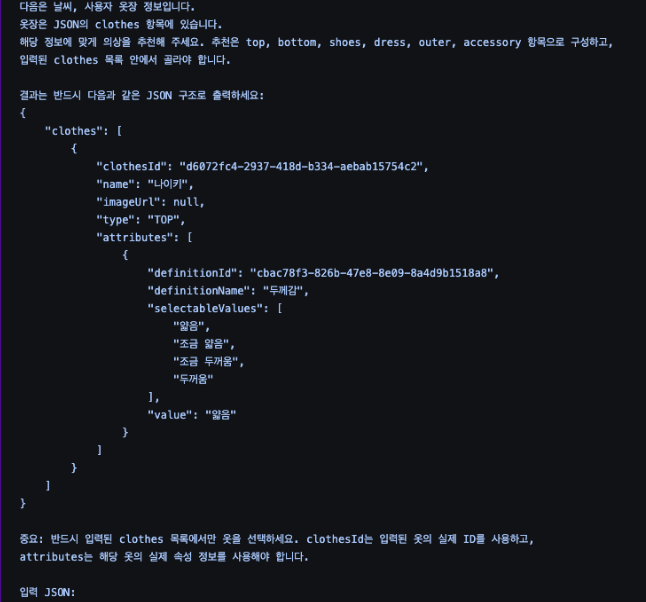
기존 프롬프트 사진
에프터 프롬프트 사진

프롬프트를 수정하여 일관된 답변을 하도록 유도했다.
응답 지연
두 번째로는 의상 추천 버튼을 누르면 약 20초 정도의 지연이 발생했다.
간단한 서비스가 20초 정도로 느리면 매우 느린 성능으로 사용자 이탈 가능성이 충분하다고 생각했고, 매우 크리티컬하다고 생각했다.
매우 느린 성능을 끌어 올리기 위해 먼저 LLM 모델을 비교했다.
기존 모델은 gpt-4o-mini를 사용하고 있었다.




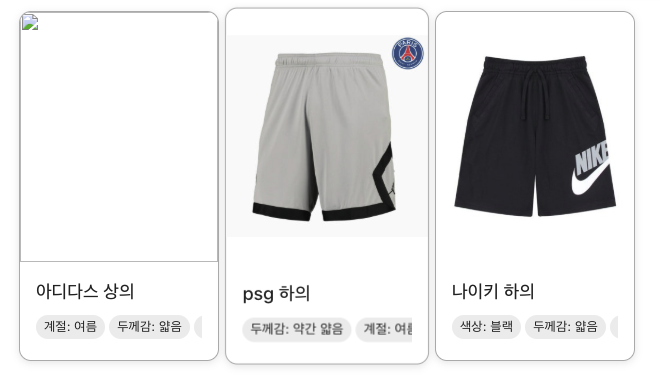
위 사진처럼 의상 추천을 보여주기까지 약 20초 정도가 걸리고, 하의를 두 개 추천하는 것처럼 자연스럽지 못한 추천을 했다.
다음으로 gpt-4.1-mini를 사용해보았다.




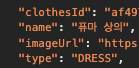
기존 4o-mini보다 약간 빨랐지만, 퓨마 상의는 type이 TOP으로 설정되어 있었지만, gpt가 임의로 DRESS로 바꾸어 출력하는 것을 볼 수 있었다.
다음으로는 gpt-4.1-nano이다.



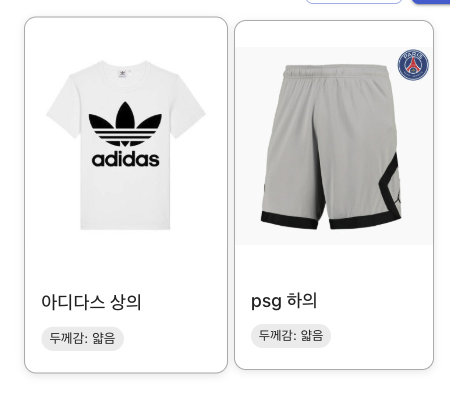
위의 모델들 보다는 확실히 빠르고, 일관된 답변을 했지만, 속성을 마음대로 바꾸고, 자세하게 출력하지 않았다.
마지막으로 gpt-3.5-turbo를 사용했다.




gpt-3.5-turbo 모델이 위에서 사용했었던 모델들보다 확실히 좋다고 느꼈다.
응답시간도 가장 빨랐고, 답변도 일관됐고, 의도한 답변을 했었다.
gpt-4o-mini, gpt-4.1-mini, gpt-4.1-nano, gpt-3.5-turbo 비교를 해봤을 때 가장 적합한 모델은 3.5-turbo이기 때문에 기존 4o-mini에서 교체를 했다.
이를 통해 기존 약 20초 넘던 응답시간이 7초로 줄어들게 됐다.
하지만 7초의 응답시간도 매우 느리다고 생각해서 어떻게 줄여야할지 고민을 해봤다.
비동기는 어차피 gpt 응답을 기다려야 하기에 의미가 없다고 생각했다.
캐시는 두 번째 조회부터 적용되니까 이것도 의미가 없다고 생각하던 중 좋은 생각이 들었다.
미리 추천을 받아서 캐시에 저장해놓고 사용자가 추천을 누르면 반환하면 해결할 수 있을 것 같았다.
스프링의 카페인 캐시는 성능이 매우 빠르고 간단하지만, JVM 로컬 캐시이기 때문에 인스턴스가마다 따로 저장되고, 메모리 용량 초과시 TTL이 보장되지 않기 때문에 적합하지 않다고 생각했다.
그렇기에 모든 인스턴스에서 동일한 캐시를 공유할 수 있고, 24시간 TTL 보장을 해주는 Redis가 더 적합하다고 생각해 Redis를 사용했다.
최종 구현
최종적으로 구현한 로직은
배치 작업을 통해 새벽에 LLM의 의상 추천 결과를 생성하여 Redis에 캐싱 후 사용자가 의상 추천 클릭 시 캐싱된 데이터를 반환하도록 만들었다.
이를 통해 기존 응답시간이 7초에서 82ms로 단축할 수 있었다.
남은 문제점 및 개선 방향
@Async("preloadTaskExecutor")
@Scheduled(cron = "0 0 6 * * *", zone = "Asia/Seoul") // 매일 오전 6시
public void preloadMorningRecommendations() {
log.info("의상 추천 배치 시작");
long startTime = System.currentTimeMillis();
int successCount = 0;
int totalUsers = 0;
int usersWithLocation = 0;
try {
// 전체 날씨 데이터 개수 확인
List<Weather> allTodayWeathers = weatherRepository.findAll().stream()
.filter(w -> w.getForecastAt().toLocalDate().equals(LocalDate.now()))
.collect(Collectors.toList());
log.info("오늘자 전체 날씨 데이터 개수: {}, 지역: {}",
allTodayWeathers.size(),
allTodayWeathers.stream().map(Weather::getRegionName).distinct().collect(Collectors.toList()));
List<User> users = userRepository.findAll(); // TODO:로그인 기록이 있으면 좋은데 없으니 일단 모든 유저
totalUsers = users.size();
for(User user : users) {
if (user.getLocation() != null) {
usersWithLocation++;
}
try{
preloadUserRecommendations(user);
successCount++;
} catch (Exception e) {
log.warn("사용자 추천 배치 실패 : user = {}, error = {}", user.getId(), e.getMessage());
}
}
long duration = System.currentTimeMillis() - startTime;
log.info("의상 추천 배치 완료: 총 {}명, location 있는 사용자 {}명, 성공 {}명, 소요시간 {}ms",
totalUsers, usersWithLocation, successCount, duration);
} catch (Exception e) {
log.error("의상 추천 배치 전체 실패", e);
}
}
하지만 몇 가지 문제가 있는데, List<User> users = userRepository.findAll(); 이 부분이다.
첫 번째로는 현재 User 테이블에는 로그인 기록이 없어서 모든 유저들을 가져와 배치 작업을 해야하는데, 상당히 비효율적이다.
향후 로그인 기록을 추가하여 필터링을 해야한다.
두 번째로는 유저 프로필에 현재 위치 설정을 누르지 않으면 유저 테이블에 location_id가 입력되지 않는다.
즉, 배치 작업을 하려면 유저 테이블에 location_id가 존재해야 하는데 새로 회원가입한 유저나, 프로필에서 현재 위치 설정을 하지 않은 유저는 의상 추천 서비스를 처음 7 ~ 8초 정도를 기다려야 한다.
이부분은 조금 더 고민해봐야겠다.