회고
캐시 도입
개요
이번에 리팩토링 할 부분은 인기 리뷰쪽 캐싱인데요 ! 인기 리뷰는 스프링 배치로 매일 정각에 업데이트가 되어 조회를 하게 되는데, 캐싱을 이용하여 인기 리뷰 조회 성능을 개선 할 수 있을 것 같아서 도전을 해보려 합니다.
Redis vs Caffeine
캐시에는 여러 툴을 사용할 수 있는데, 제가 고려했었던 선택지는 Redis와 Spring Cache 중 Caffeine 두 가지였습니다.
Caffeine은 JVM 내에서 작동하는 로컬 캐시로 접근 속도가 매우 빠른게 장점이고,
Redis는 키값 구조이며, 다양한 데이터 구조를 지원하고, 비동기 처리 및 분산처리를 위한 기능을 제공하기 때문에 고성능 시스템에서 널리 쓰이고 있습니다.
제가 구현한 인기 리뷰 조회는 실제로 단순 조회 API이고, 캐시도 공유될 필요가 없기 때문에 Caffeine을 선택하게 됐습니다.
설정
먼저 build.gralde 에서 의존성을 추가합니다.
// Spring Cache
implementation 'org.springframework.boot:spring-boot-starter-cache'
implementation 'com.github.ben-manes.caffeine:caffeine:3.1.8'
의존성을 추가하고 CacheConfig를 구현하면
@Configuration
@EnableCaching
@Slf4j
public class CacheConfig {
@Bean
public CacheManager cacheManager() {
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
// Caffeine 캐시 설정
cacheManager.setCaffeine(Caffeine.newBuilder()
.maximumSize(50) // 최대 캐시 크기
.expireAfterWrite(Duration.ofMinutes(55)) // 55분 만료
.removalListener((key, value, cause) ->
log.info("캐시 제거 : 키={}, 값={}, 원인={}", key, value, cause))
);
// 캐시 이름 등록
cacheManager.setCacheNames(Arrays.asList("popularReviews", "reviewStats"));
return cacheManager;
}
@Bean
public CacheErrorHandler cacheErrorHandler() {
return new SimpleCacheErrorHandler() {
@Override
public void handleCacheGetError(RuntimeException exception, Cache cache, Object key) {
log.warn("캐시 조회 오류: 키={}, 오류={}", key, exception.getMessage());
// 에러 발생 시 DB에서 조회하도록 무시
}
@Override
public void handleCachePutError(RuntimeException exception, Cache cache, Object key,
Object value) {
log.warn("캐시 저장 오류: 키={}, 값={}, 오류={}", key, value, exception.getMessage());
// 에러 발생 시 캐시 저장 실패해도 계속 진행
}
};
}
}
위에서 언급한대로 Caffeine을 사용했고, 설정을 간단히 설명하면
.maximumSize(50) 최대 캐시 크기로 현재 인기 리뷰를 보면
PeriodType : DAILY, WEEKLY, MONTHLY, ALL_TIME
Drection : ASC, DESC
Limit : 20
타입 4개, 방향 2개, 클라이언트 요청에 따라 리밋은 바뀔 수 있음으로 4 * 2 * 2 = 16개 정도 실제 가능한 조합이지만, 여유롭게 50개 정도로 설정했습니다.
.expireAfterWrite(Duration.ofMinutes(55)) // 55분 만료
현재 스프링 배치가 매 정각마다 실행이 되기 때문에 55분 만료로 설정해 캐시 미스를 방지했습니다.
@Cacheable
@Override
@Cacheable(
value = "popularReviews",
key = "#period.name() + '_' + #direction.name() + '_' + #limit",
condition = "#cursor == null", // 첫 페이지만 캐싱
unless = "#result.content.isEmpty()" // 빈 결과는 캐싱하지 않음
)
public CursorPageResponsePopularReviewDto getPopularReviews(
PeriodType period, Direction direction, String cursor, Instant after, Integer limit) {
이렇게 메서드에 @Cacheable 애노테이션을 이용해 캐시를 사용할 수 있습니다.
value엔 앞에 config에서 설정한 이름을 넣어주고
key를 통해 캐시 키를 생성합니다. #파라미터명 으로 값 접근이 가능합니다.
condition을 통해 첫 페이지만 캐싱한다는 조건을 넣어줍니다.
첫 페이지만 캐싱하는 이유 → 첫 페이지는 자주 조회되기 때문에 캐시 효과가 크지만 2, 3페이지는 가끔 조회되기 때문에 메모리가 낭비된다고 생각해 첫 페이지만 캐싱했습니다.
unless를 통해 빈 데이터 캐싱을 방지합니다.
결론
먼저 포스트맨을 이용해 캐시 적용을 안하고 요청을 보내면
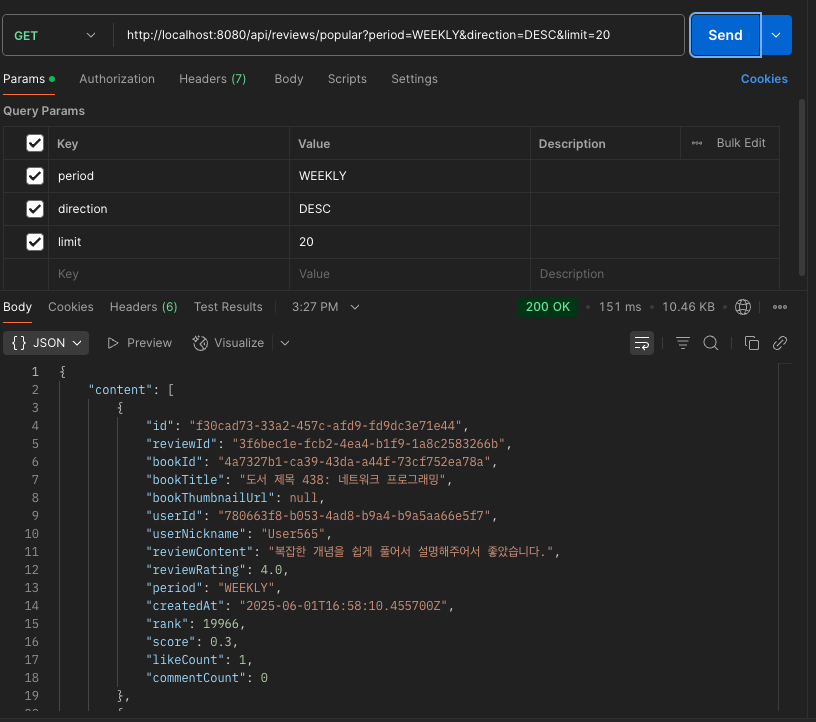
151ms가 걸린걸 알 수 있습니다.
다음으로 캐시를 적용하고 요청을 보내면
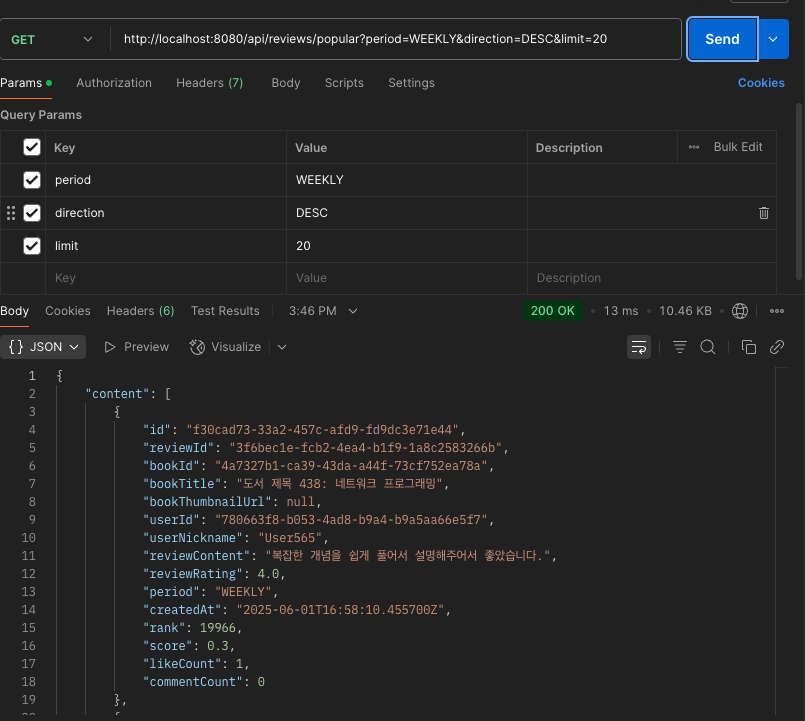
13ms..
151ms → 13ms 약 91퍼 개선이 됐습니다. 생각보다 엄청 개선이 됐습니다.
캐시를 이번에 리팩토링하며 처음 도입해봤는데 생각보다 조회 성능이 엄청 개선된게 체감될 만한 수치인 것 같습니다.
특히 정적이고 반복 조회가 많은 데이터에 캐시를 적용했을 때 엄청 강력한 것 같습니다.
복잡한 로직을 추가한 것도 아니고 간단하게 Config 설정하고 Service에 @Cacheable 설정을 했을 뿐인데 간단한 작업으로도 이렇게 개선되는게 놀라울 뿐입니다..ㅎ
곧 다음 팀 프로젝트가 시작되는데 다음 팀 프로젝트에서는 이번 리팩토링으로 얻은 것들을 적용하면서 구현해야겠습니다.
성능 개선이 눈에 바로 보이다보니 생각보다 재밌네요 ㅎㅎㅎ.. 다음 프로젝트 시작하기 전까지 리팩토링을 좀 더 진행하면서 연습을 좀 해야겠습니다 !