Project
옷장을 부탁해
실시간 날씨 정보를 기반으로 개인화된 의상을 추천하고, 사용자들이 자신의 옷차림(OOTD)을 공유할 수 있는 소셜 플랫폼
역할
백엔드 및 인프라 개발
기간
2025.06 ~ 2025.07
스택
Java, Spring Boot, Spring Data JPA, QueryDSL, PostgreSQL, Redis, MongoDB, Docker, AWS ECS/S3/ECR, Grafana, Prometheus, OpenAI API
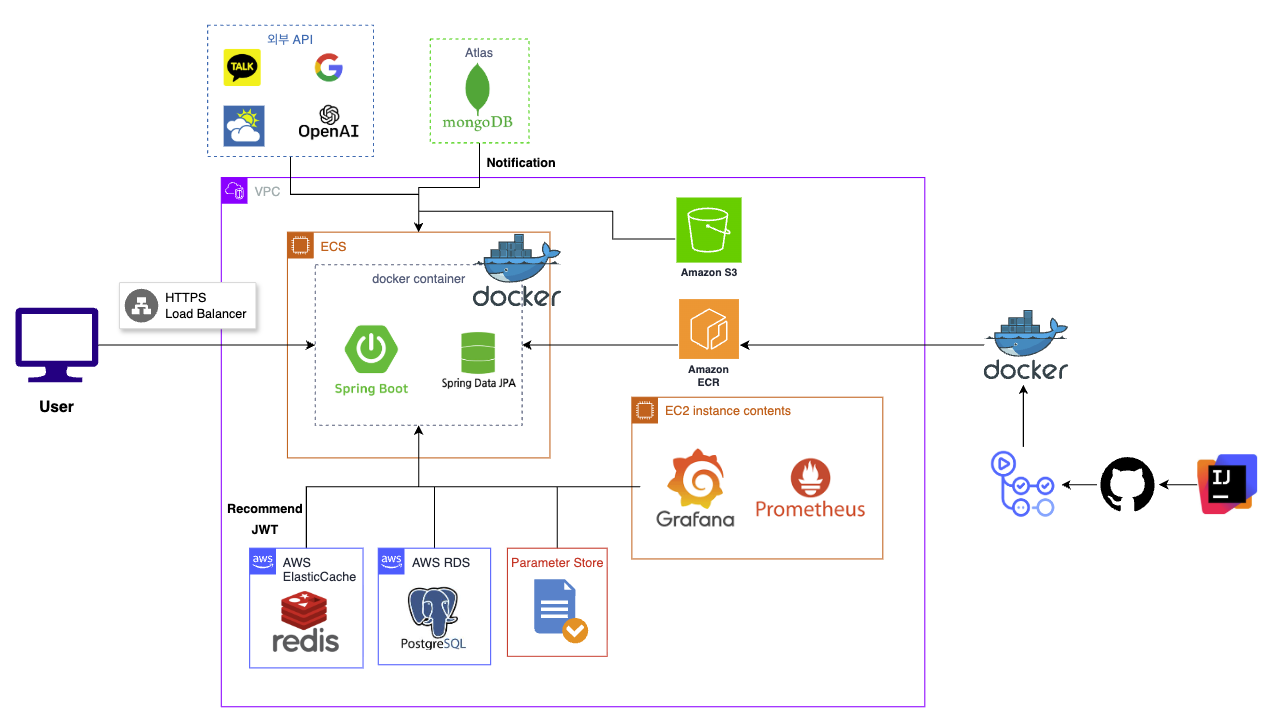
아키텍쳐
트러블슈팅 #1 — 의상 추천 로직 리팩토링
문제 상황
- 단일 쿼리에서 조회, 계산, 로직 처리를 모두 담당하여 복잡도 증가하는 문제
- 비즈니스 로직 변경 시 SQL 수정 필요해 유지보수성 저하가 되는 문제
해결 방식
- 관심사 분리 원칙 적용
- Repository: DB 조회만 담당
- Service 레이어:
ClothesCalculator,ClothesSelector클래스로 기능 분리 후Service에서 조립
결과
- 코드 가독성 및 유지보수성 향상
- 비즈니스 로직 변경 시 Java 코드만 수정 → 컴파일 에러 체크 가능
트러블슈팅 #2 — LLM 기반 의상 추천 서비스 성능 최적화
기존 의상 추천 로직은 한 쿼리문에서 조회, 계산까지 처리를 담당하는 책임이 아주 많았다.
한 쿼리문에서 모든 것을 해결하기 때문에 의상 추천 로직 추가시 복잡도가 갈수록 높아지고, 유지보수성이 매우 낮아지는 문제점이 있었다.
구현한 의상 추천 로직에 대해 간단히 설명하자면 사용자의 온도 민감도, 날씨정보, 옷들의 정보를 조인
체감온도 + 사용자의 온도 민감도 + (강수 유무에 따른 온도 조정) 을 계산하고
총 합 온도에 맞춰서 구역을 나눈 뒤 옷의 두께감, 색상, 계절에 맞는 옷 속성에 따라 점수를 차등 지급하여 점수에 따라 내림차순으로 정렬 후 각 카테고리(상의, 하의, 신발, 원피스, 아우터 등등)를 1개씩 출력해주는 로직이다.
처음에는 옷의 두께감만 기준으로 잡았기에 쿼리문 하나로 해결했지만, 로직이 늘어남에 따라 유지보수에 어려움을 느꼈고, 쿼리문에서 너무 많은 책임을 지고 있었기에 계산 로직을 서비스 레이어로 분리를 했다.
기존 쿼리 로직
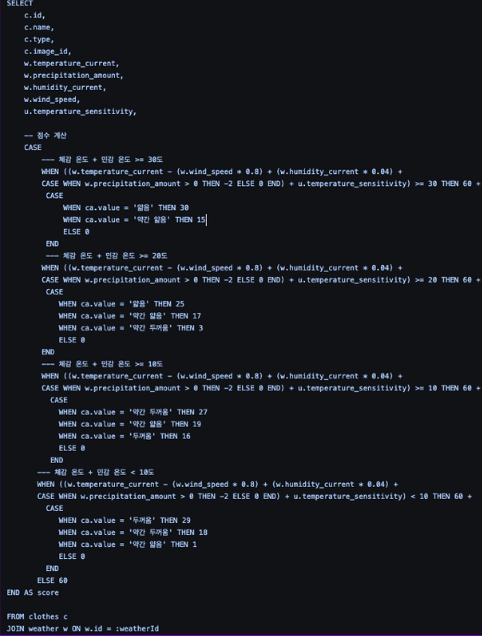
이런식으로 기존 쿼리문은 하드 코딩으로 이루어져 있었기 때문에 로직을 추가하려면 다음과 같이 하드코딩을 했어야 했다.
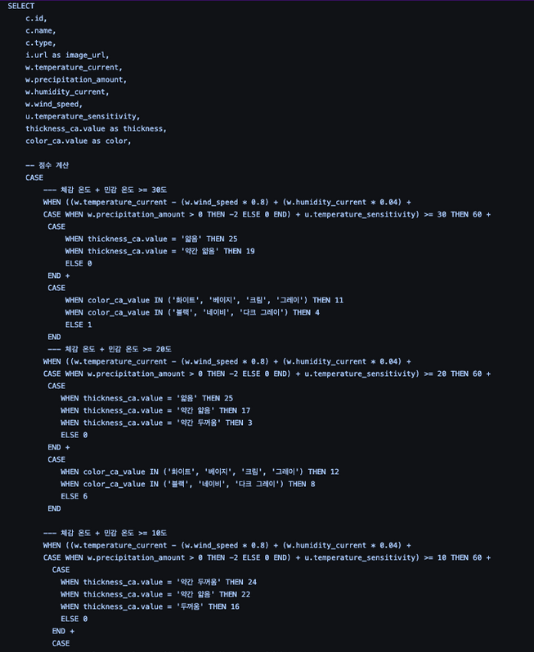
레이어 분리
그래서 선택한 것이 리팩토링 방향은 비즈니스 로직을 서비스 레이어로 분리하는 것이었다.
우선 패키지 구조부터 분리했다.
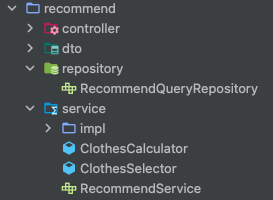
기존에는 RecommendQueryRepository에서 해결했다면,
현재 RecommendQueryRepository에서는 추천을 위한 필요 데이터 조회만 담당했다.
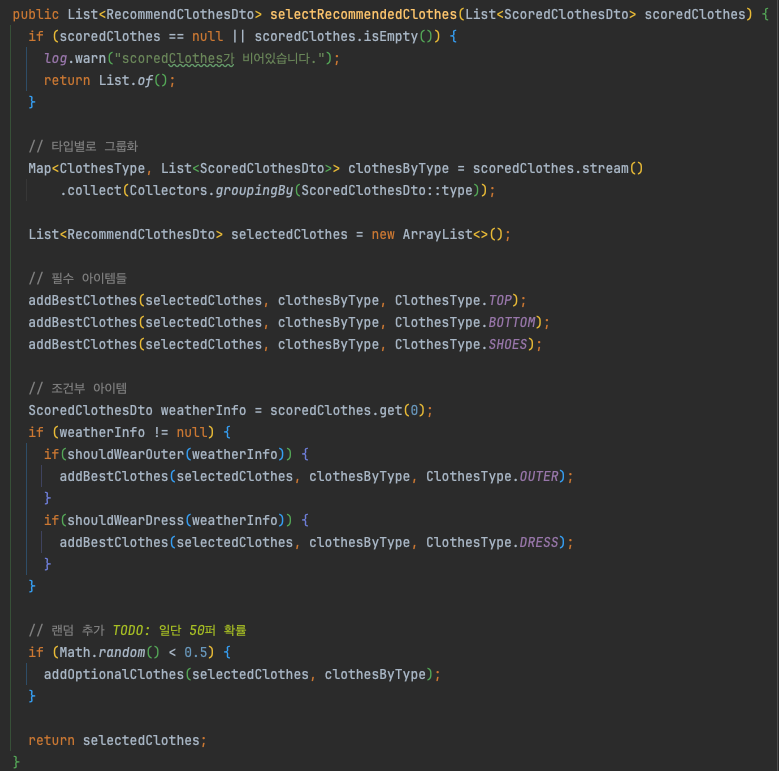
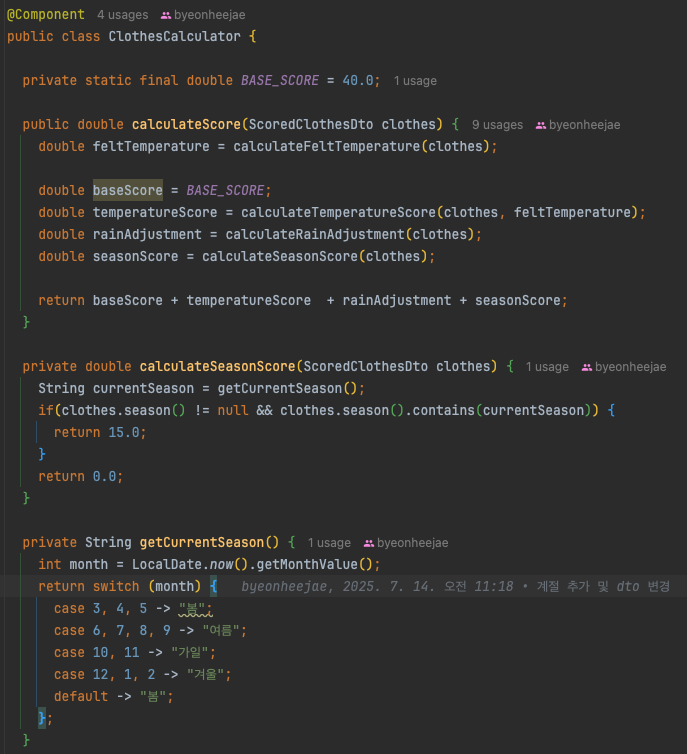
위 사진같이 ClothesCalculator에서 점수 계산, ClothesSelector에서는 점수 기준으로 옷을 분류하고 카테고리별 최종 선택으로 나누어 책임을 분리했다.
문제 상황
- 기존 서버 추천에서 AI 추천으로 수정하던 중 AI의 답변이 일관되지 않고 의도와 다른 답변을 응답
- 의상 추천 시 평균 20초 지연 발생하여 사용자 이탈 가능성 높은 문제
일관성 부족
gpt가 의도와는 다른 답변을 반환했는데, 예를 들면 상의를 두가지 추천하다던가, 하의만 추천한다던가 이러한 의도와 다르고 자연스럽지 않은 의상 추천을 했기에 더 자연스러운 추천 흐름을 만들어야 했다.
기존 프롬프트 사진
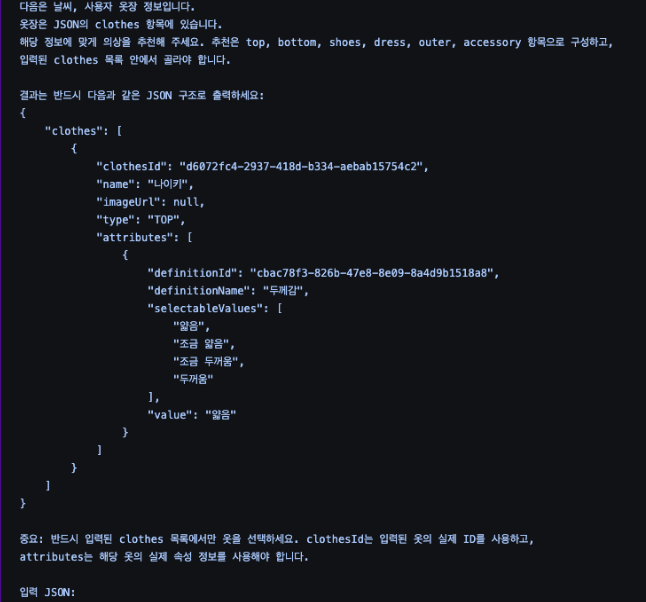
에프터 프롬프트 사진

프롬프트를 수정하여 일관된 답변을 하도록 유도했다.
응답 지연
간단한 추천 서비스가 20초 정도로 느리면 매우 느린 성능으로 사용자 이탈 가능성이 충분하다고 생각했고, 매우 크리티컬하다고 생각하여 성능을 끌어 올리기 위해 LLM 모델을 바꿔가며 응답 퀄리티와 응답 시간을 비교했다.
기존 모델인 gpt-4o-mini




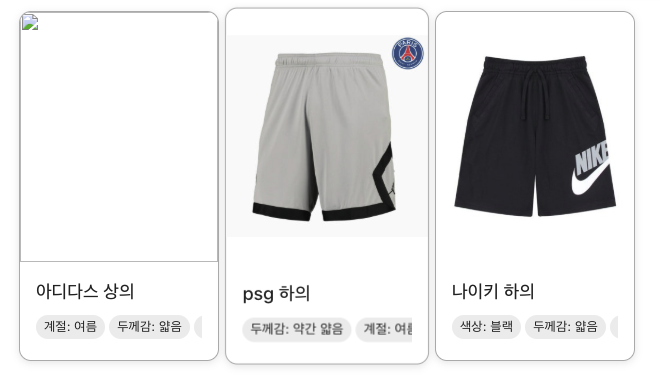
위 사진처럼 의상 추천을 보여주기까지 약 20초 정도가 걸리고, 하의를 두 개 추천하는 것처럼 자연스럽지 못한 추천을 했다.
gpt-4.1-mini




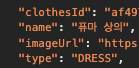
기존 4o-mini보다 약간 빨랐지만, 퓨마 상의는 type이 TOP으로 설정되어 있었지만, gpt가 임의로 DRESS로 바꾸어 출력하는 것을 볼 수 있었다.
gpt-4.1-nano



위의 모델들 보다는 확실히 빠르고, 상대적으로 일관된 답변을 했지만, 속성을 마음대로 바꾸고, 자세하게 출력하지 않았다.
gpt-3.5-turbo




gpt-3.5-turbo 모델이 다른 모델에 비해 응답시간도 가장 빨랐고, 의도한 답변에 일관되게 응답했다.
이를 통해 기존 약 20초 넘던 응답시간이 7초로 줄어들게 됐다.
하지만 7초의 응답 시간도 매우 느려 캐싱을 사용 했지만, 첫 번째 추천에는 응답을 기다려야 하기에, 미리 추천을 받아서 캐시에 저장해놓고 사용자가 추천을 누르면 반환하게 수정했다.
모든 인스턴스에서 동일한 캐시를 공유할 수 있는 Redis를 도입했다. 스프링의 카페인 캐시는 빠르지만 JVM 기반 캐시이기 때문에 모든 유저를 캐싱하는 것엔 한계가 있다고 생각했다.
최종적으로 배치 작업을 통해 새벽에 LLM의 의상 추천 결과를 생성하여 Redis에 캐싱 후 사용자가 의상 추천 클릭 시 캐싱된 데이터를 반환하도록 만들었다.
이를 통해 기존 응답시간이 7초에서 82ms로 단축했다.
결과
LLM 응답속도 20초 → 82ms (약 99% 개선), 인프라 아키텍처 설계 및 도입